Supporting materials
Download
Download this article as a PDF





Übersetzt von Daniel Busch. Im Jahr 1953 entdeckten James Watson und Francis Crick die Struktur der DNA, dem Molekül das unsere genetischen Informationen trägt.
Im Jahr 1958 postulierte Crick dann das zentrale Dogma der Molekularbiologie: dass der Informationsfluss von DNA über RNA zum Protein abläuft. Die zentrale Frage blieb jedoch bestehen: wie codiert das Alphabet aus vier Buchstaben in der DNA (A, C, T und G) bzw. in ihrem Äquivalent der RNA (A, C, U und G) das Alphabet der zwanzig Buchstaben der Aminosäuren, die unsere Proteine bilden? Was war der genetische Code?
Im Jahr 1961 entzifferten Marshall W Nirenberg und Johann H Matthaei den ersten Buchstaben dieses Codes und enthüllten, dass die RNA-Sequenz UUU für die Aminosäure Phenylalanin codiert. Nachfolgend zeigte Har Gobind Khorana, dass die sich wiederholende Nucleotidsequenz UCUCUCUCUCUC für einen Strang der Aminosäuren Serin-Leucin-Serin-Leucin codiert. Im Jahr 1965 war der genetische Code größtenteils Dank der Arbeit von Nirenberg und Khorana vollständig entschlüsselt. Es konnte gezeigt werden, dass jede Gruppe von drei Nucleotiden (Codons gennant) für eine spezifische Aminosäure codiert, und dass die Reihenfolge der Codons die Reihenfolge der Aminosäuren des resultierenden Proteins festlegt (,und damit folglich auch dessen chemischen und biologischen Eigenschaften).

Nirenberg und Khorana verglichen kurze Sequenzen der Nukleinsäure RNA und die resultierenden Aminosäuresequenzen (Peptide). Dazu folgten Sie dem Protokoll, das Nirenberg zusammen mit Matthaei entwickelt hatte.
Dieses beinhaltete die künstliche Synthese einer spezifischen Sequenz von RNA-Nukleotiden und ihre Vermischung mit Extrakten von Escherichia coli Bakterien, die Ribosomen und andere zelluläre Strukturen enthielten, die für die Proteinsynthese nötig sind. Die Wissenschaftler bereiten dann 20 Proben der resultierenden Mischung vor, zu jeder Probe gaben sie eine radioaktiv markierte Aminosäure und 19 unmarkierte Aminosäuren, bevor sie die Proteinsynthese ablaufen ließen. Jede der 20 Probengefäße enthielt eine unterschiedliche, radioaktiv markierte Aminosäure. Wenn das resultierende Peptid radioaktiv markiert war, bedeutete das, dass die radioaktiv markierte Aminosäure einen Teil davon bildete, was wiederum bestätigte, dass die RNA-Nukleotidsequenz an irgendeiner Stelle für diese Aminosäure codierte.
Durch die Wiederholung dieses Experiments mit verschiedenen RNA-Sequenzen konnten mehr und mehr Informationen zum genetischen Code gesammelt werden. Nachdem einfach Sequenzen wie UUUUUU und AAAAAA getestet worden waren, namen sich andere Wissenschaftler der Herausforderung an, komplexere RNA-Sequenzen zu analysieren, was letztendlich zur Dekodierung aller 64 Codons führte.
Der genetische Code ist ein wesentliches Element des Biologieunterrichts, das eine molekulare Erklärung für das Verhalten von Genen liefert (z.B. bei Mutationen, in der Evolution und bei der Genexpression). Die Art und Weise, wie Nirenberg und Khorana den genetischen Code geknackt haben – nämlich durch den Vergleich kurzer RNA-Sequenzen mit den resultierenden Aminosäuresequenzen – kann des Weiteren als forschend-entdeckende Unterrichtsaktivität an Schulen nachgemacht werden. Unter Verwendung der Sequenzen, die vom Lehrer zur Verfügung gestellt werden, lernen die Schülerinnen und Schüler in Gruppen an:
Die Aktivität bietet somit ein Unterrichtsmodell für die Natur des wissenschaftlichen Wissenserwerbs: ein provisorischer, von der Gemeinschaft konstruierter Konsens basierend auf vorläufigen Beweisen.
Diese Aktivität richtet sich an Schülerinnen und Schüler im Alter von 14-18, die in Dreier- oder Vierergruppen arbeiten, und beansprucht etwa zwei Stunden unterteilt in vier Schritte und einer Abschlussdiskussion. Sie wurde als eine Einführung in die Molekularbiologie erstellt, bevor der genetischen Code oder das zentrale Dogma der Molekularbiologie eingeführt wurden.
Von den Studenten wird erwartet, den Code aus verschiedenen Basensequenzen (A, C, T, G) zu entschlüsseln, wobei Ihnen die Informationen helfen, die diese Sequenzen codieren (z.B. Asp-His-Trp…). In jedem der drei ersten Schritte bekommt jede Gruppe einen unterschiedlichen Satz an Basensequenzen und korrespondierende Informationen. Mit jedem Schritt müssen sie ihre Ergebnisse der vorherigen Schritte erneut evaluieren und an den Code anpassen.
Erklären Sie allen Gruppen, dass sie den selben Code knacken, aber dafür verschiedene Beispiele verwenden. Erzählen Sie den Schülerinnen und Schülern nichts über die biologische Natur der Sequenzen (DNA und Aminosäuren); sie sollen sich darauf konzentrieren Muster und Gemeinsamkeiten zu finden.
Nirenberg und Khorana benutzten RNA-Sequenzen zum Knacken des Codes, im Gegensatz dazu greift diese Aktivität auf die DNA-Sequenzen (Sense Codon, 5’ zu 3’) zurück. Der Schlüssel der Aktivität ist eher die Existenz des Codes als die Details von Transkription und Translation, welche in den Folgestunden thematisiert werden können.
Nach jedem Arbeitsschritt könnten Sie eine/n Schüler/in bitten, sich einer anderen Gruppe anzuschließen. (Dies simuliert die Dynamik des wissenschaftlichen Wissenserwerbs und der Wissensweitergabe auf Konferenzen oder über Publikationen.)
Alternativ können die Gruppen ihr Wissen austauschen, wenn sie dazu aufgefordert werden. (Wenn eine Gruppe nicht weiterkommt und entmutigt wird, kann es motivierender sein, eine andere Gruppe um Rat zu fragen als den Lehrer.)
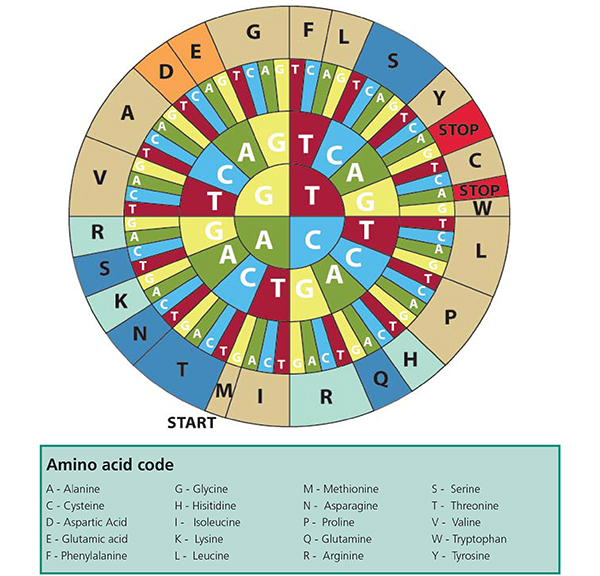
Geben Sie ihren Schülerinnen und Schülern mindestens 10-15 Minuten Zeit für Diskussionen pro Arbeitsschritt. Wenn alle Gruppen das Gefühl haben, sich alle möglichen Informationen aus ihren Sequenzen erarbeitet zu haben, leiten Sie den nächsten Schritt ein.
| Sequenz: | Bedeutung | Schülerinnen und Schüler erkennen, dass… |
|---|---|---|
| ATGTTAGGTAGTAAAGATGCT | MetLeuGlySerLysAspAla | Der Code basiert auf Tripletts und jedes Triplett repräsentiert ein dreibuchstabiges Element, z.B. Met. |
| ATGCATGAAGCTATTTATGAT | MetHisGluAlaIleTyrAsp | |
| ATGGGTAGTGATGAAGCTTAT | MetGlySerAspGluAlaTyr |
| Sequenz | Bedeutung | Schülerinnen und Schüler erkennen, dass… |
|---|---|---|
| ATGGTTTCGTACACTGCGTCA | MetValSerTyrThrAlaSer | einige Elemente von mehrern Tripletts codiert werden können, z.B. Ser. |
| ATGCCGTACACATGTGTCACA | MetProTyrThrCysValThr | |
| ATGACGAGTGCGTTGTGCGAT | MetThrSerAlaLeuCysAsp |
| Sequenz | Bedeutung | Schülerinnen und Schüler erkennen, dass… |
|---|---|---|
| TGTCATGCATCCGTCATCACTGAC | – | Das ATP-Triplett den Anfang des Codes darstellt und das TGA-Triplett sein Ende. |
| TGCGTGACTATGGACACAGTCGT | MetAspThrVal | |
| ATGTGTCGATGACTGATCATG | MetCysArg | |
| ATGTGCGTACACATTTGAGTC | MetCysValHisIle | |
| ATGCTGTACACATGATGCACAGT | MetLeuTyrThr |

Stellen Sie ihren Schülerinnen und Schüler folgende Fragen:
Erklären Sie ihren Schülerinnen und Schülern nach der Diskussion, dass die Sequenzen DNA- und Aminosäuresequenzen waren und dass sie gerade ein echtes Schlüsselexperiment der Molekularbiologie reproduziert haben. Ihre Lernenden sollten nun motiviert sein, mehr über den genetischen Code und das zentrale Dogma der Molekularbiologie zu lernen, inklusive der Einsicht, wie ähnlich ihre Aktivität zu der Art und Weise war, wie der genetische Code wirklich geknackt wurde.
Sie sollten die Aktivität zusammenfassen, indem Sie ihre Lernenden daran erinnern, was sie für sich selbst entdeckt haben:
(Bedenken Sie, dass die Aktivität die Fehlvorstellung hervorrufen könnte, dass Proteine meistens aus sechs oder sieben Aminosäuren aufgebaut sind. Dies könnte noch angesprochen werden.)
Machen Sie deutlich, dass die Arbeitsweise, in denen ihre Lernenden gearbeitet haben, nämlich die Arbeit in sich verändernden Teams, die gleichzeitig zusammenarbeiten und konkurrieren und der Weitergabe von Informationen an die anderen Teams, die Art und Weise darstellen, in der Wissenschaftler auch im echten Leben arbeiten.
Um die Aktivität etwas einfacher zu machen, können Sie ihren Schülerinnen und Schülern mehr Sequenzen in jedem Schritt zur Verfügung stellen (z.B. die Sequenzsets von zwei Gruppen). Alternativ könnten Sie Schritt 3 auslassen und lediglich am Ende der Aktivität erklären, welche Rolle das Start- und Stopp-Codon haben.
Pädagogische Reflexionen zu Aktivitäten wie der aus diesem Artikel sind ein Teil der Arbeit der Forschungsgruppe LICEC (llenguatge i contextos en educació científica, Sprache und Kontext in der wissenschaftlichen Bildung) an der Freien Universität Barcelona (Referenznummer 2014SGR1492), finanziert vom Spanischen Ministerium für Wirtschaft und Wettbewerb (Referenznummer EDU2015-66643-C2-1-P)
w1 – Die Website des Nobelpreises bietet eine Tabelle zur Übersetzung von Codons in Aminosäuren.
Dieser Artikel bietet Lehrern eine einfache und zugängliche Strategie, eine der herausforderndsten Aspekte des naturwissenschaftlichen Unterrichts zu entdecken: ihren Lernenden zu vermitteln, wie wissenschaftliches Arbeiten wirklich funktioniert. Der Wissenserwerb erfordert das Stellen guter Fragen, die Planung und Durchführung guter Experimente, und die Zusammenarbeit bei der Überprüfung von Unsicherheiten. Genau dies wird von den Schülerinnen und Schülern bei dieser Aktivität erwartet, wenn sie den genetischen Code knacken.
Ich gehe davon aus, dass Lehrer anderer Disziplinen als der Biologie (insbesondere der Mathematik und Chemie) diesen Artikel ebenfalls nützlich finden werden. Es wäre ebenfalls eine sehr gute Aktivität für eine Wissenschaftsmesse.
Betina Lopes, Portugal
Download this article as a PDF