




Pouvez-vous détecter une mutation cancérogène? Teach article
Traduit par Claire Batisse. Comment se développe un cancer, et comment les généticiens peuvent-ils dire qu’une cellule est cancéreuse? Cette activité pédagogique développée par l’équipe "Communication and Public Engagement" du Wellcome Trust Sanger Institute, en Grande-Bretagne,…
Tous les cancers résultent de changements de la séquence ADN dans certaines de nos cellules. Des erreurs peuvent s’accumuler pendant la réplication parce que le matériel génétique dans les cellules est exposé à des agents mutagènes tels que les rayons UV. Occasionnellement, une de ces mutations altère la fonction d’un gène essentiel, fournissant un avantage de croissance à la cellule dans laquelle elle a eu lieu et à ses descendantes; ces cellules se diviseront plus rapidement que leurs voisines.
Petit à petit, l’ADN acquiert plus de mutations, qui peuvent conduire à la perturbation d’autres gènes clé, ayant pour conséquence des cellules invasives à croissance particulièrement rapide. Il en résulte la formation d’une tumeur, l’invasion des tissus environnant et finalement des métastases –propagation du cancer dans les autres parties du corps.
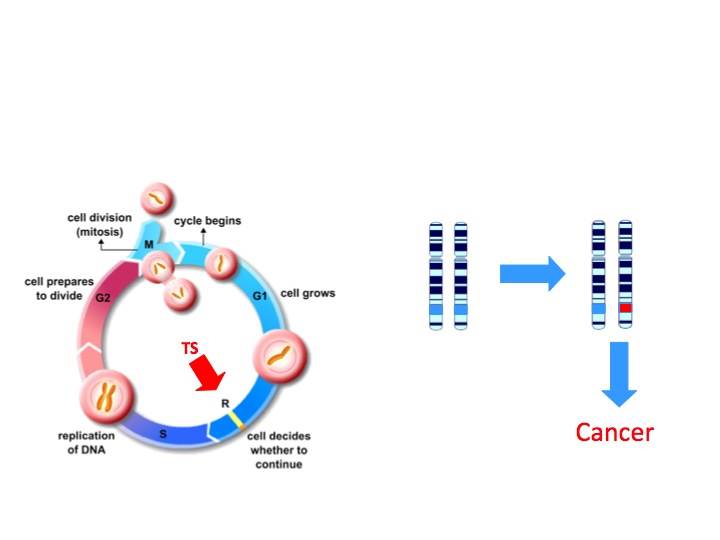
de tumeurs fonctionnant
normalement pour prévenir
la croissance et la division
cellulaire. Pour conduire au
cancer, les deux copies d’un
gène devront être mutées
(marquées en rouge). Cliquer
sur l’image pour l’agrandir
Image reproduite avec
l’aimable autorisation de the
Wellcome Trust Sanger
Institute Communication and
Public Engagement team
Les gènes qui conduisent au développement de cancers quand ils sont mutés sont connus comme «gènes du cancer».
Les gènes suppresseurs de tumeurs (GSTs; Figure 1) code l’information pour faire des protéines qui normalement diminuent la croissance cellulaire, prévenant les divisions non nécessaires ou favorisant l’apoptose (mort cellulaire programmée) si l’ADN de la cellule est endommagé. Les deux copies d’un GST devront être inactivées par mutation avant que ce contrôle du cycle cellulaire soit perdu. Si une copie reste fonctionnelle, il y a encore un «frein» à la croissance cellulaire.
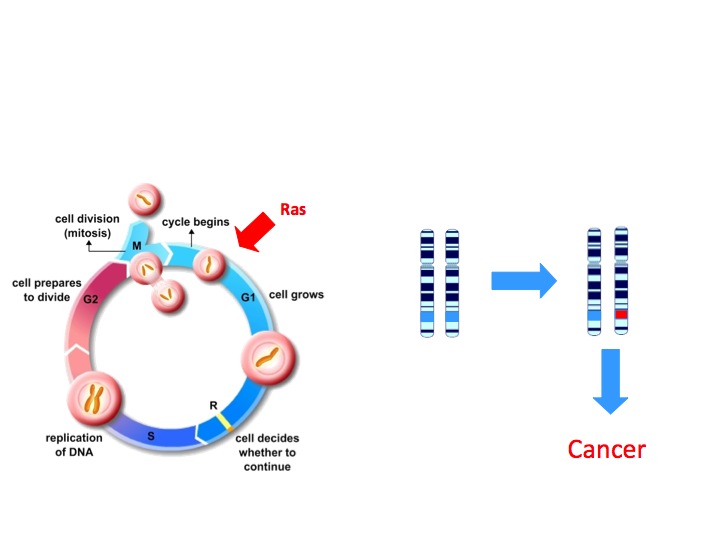
oncogènes fonctionnent
normalement pour favoriser
la croissance et la division
cellulaire d’une manière
contrôlée. La mutation d’une
copie du gène (marquée en
rouge) peut être suffisante
pour conduire au
développement d’un cancer.
Cliquer sur l’image pour
l’agrandir
Image reproduite avec
l’aimable autorisation de the
Wellcome Trust Sanger
Institute Communication and
Public Engagement team
Les proto-oncogènes (Figure 2), au contraire, codent des protéines qui favorisent la division et la différenciation cellulaire (spécialisation). Lorsque ces gènes acquièrent des mutations qui font des protéines continuellement actives ou conduisent à ce que l’activité du gène ne soit plus régulée, ils deviennent des oncogènes, favorisant la croissance et la division cellulaire incontrôlée. Pour les proto-oncogènes, une mutation d’une copie du gène peut être suffisante pour conduire au développement d’un cancer.
Chaque cas de cancer est causé par un ensemble unique de mutations dans des proto-oncogènes et/ou des GSTs. Bien que le nombre ne soit pas encore connu, on suppose qu’au moins 5 mutations dans les gènes de cancer sont nécessaires pour qu’une cellule (et ses descendantes) devienne cancéreuse.
KRAS (prononcé ka-rass) est un proto-oncogène qui code la protéine KRAS, une protéine de signal intracellulaire impliquée dans la stimulation de la croissance cellulaire (pour distinguer les gènes des protéines, les noms des gènes sont écrits en italique par convention). L’activité suivante permet aux étudiants d’utiliser les données duCancer Genome Projectw1 pour étudier les mutations communes dans le gène KRAS qui sont associées avec l’oncogenèse (formation de cancer) et le développement de cancers pancréatiques, colorectaux, des poumons et bien d’autres. Développée à l’origine pour des visites scolaires au Sanger Institutew2, l’activité a été mise à disposition sur le site web Yourgenome.orgw3. Elle a récemment formé une partie du premier cours en bioinformatique pour les enseignants européens organisé par ELLSw4 au « European Bioinformatics Institutew5 à Hinxton, en Grande-Bretagne. Dans son intégralité, l’activité stimule la discussion sur les causes du cancer, la fonction des mutations des gènes, la structure et la fonction des protéines.
L’activité de KRAS

séquence du gène KRAS.
Cliquer sur l’image pour
l’agrandir
Image reproduite avec
l’aimable autorisation de the
Wellcome Trust Sanger
Institute Communication and
Public Engagement team
Durée estimée: 45–60 minutes (avec la présentation et la discussion)
Matériels
Tous les matériaux requis pour faire l’activité peuvent être gratuitement téléchargés à partir du site web Yourgenome.org soit individuellement ou sous forme de fichier compressé zipw6.
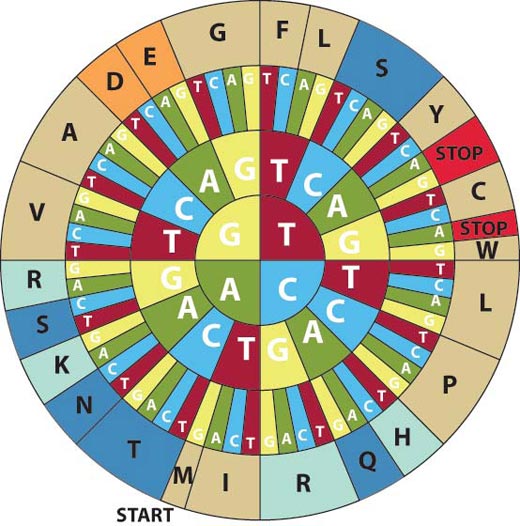
roue du code génétique pour
traduire les codons ADN en
acides aminés. Pour décoder
un codon, trouver la première
lettre de votre séquence dans
le cercle interne et travailler
vers l’extérieur pour voir
l’acide aminé correspondant.
Par exemple, CAT code pour
H (histidine). Noter que ce
diagramme utilise le sens
ADN codons (5’-3’). Cliquer
sur l’image pour l’agrandir
Image reproduite avec
l’aimable autorisation de C
Brooksbank, European
Bioinformatics Institute
- Un ensemble de 11 feuilles de travail (KRAS_student_wsheet.pdf) – une feuille de travail par paire ou groupe d’étudiants. Une version alternative est disponible pour imprimantes en noir et blanc ou pour des étudiants daltoniens. Pour de grands groupes (20 ou plus), utiliser 2 ensembles de feuilles de travail, fournissant une double couverture du gène.
- Une bannière de la séquence du gène (KRAS_gene_banner.pdf) pour l’ensemble de la classe, et une feuille avec la séquence du gène KRAS (KRAS_genesheet_yg.pdf; Figure 3) par groupe d’étudiants. La feuille de gène (imprimée en A3 ou A4) requiert un petit temps de préparation. La bannière KRAS, imprimée sur plusieurs feuilles de papier qui sont alors collées ensemble, permet aux résultats de l’ensemble de la classe d’être montrés simultanément.
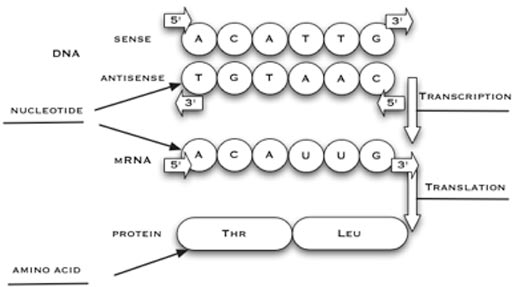
synthétisé à partir du brin
anti-sens de l’ADN. Le brin
sens de l’ADN, utilisé dans
cette activité, a la même
séquence que le brin d’ARN
correspondant, sauf que les T
sont remplacés par des U.
Cliquer sur l’image pour
l’agrandir
Image reproduite avec
l’aimable autorisation de
Cleopatra Kozlowski
- Une feuille avec la roue du code génétique (KRAS_codon_wheel.pdf ou n’importe quelle table du code génétique pour l’ADN dans le sens 5’-3’) par groupe (voir Figures 4 and 5)
- Une feuille de résumé (KRAS_ data_sheet.pdf) par groupe
- Des stylos
Pour utiliser la bannière, vous aurez aussi besoin de grandes flèches pour marquer les mutations, de carrés pour marquer les régions qui ont été vérifiées (KRAS_annotations.pdf), et de l’adhésif réutilisable (comme Blu Tack®) pour coller les flèches et les carrés sur la séquence du gène. Vous trouverez plus de renseignements sur la façon d’utiliser cette méthode dans les notes pour enseignants téléchargeablesw6.
De plus, vous pourrez trouver utile d’avoir le modèle de l’ADN, du peptide et/ou de la protéine pour manipulation, et d’utiliser les animations sur le cancer du Wellcome Trust Sanger Institute (Cancer: Rogue cells et Role of cancer genes) sur le site web de l’activité KRASw6.
Introduction à l’activité
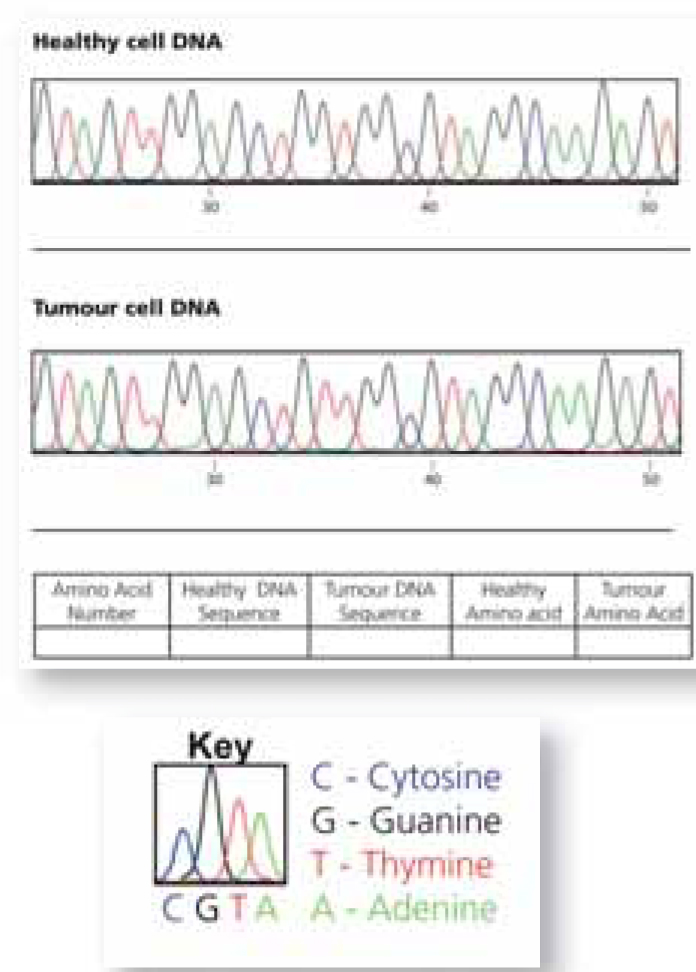
feuille de travail d’un
étudiant. Cliquer sur l’image
pour l’agrandir
Image reproduite avec
l’aimable autorisation de the
Wellcome Trust Sanger
Institute Communication and
Public Engagement team
La présentation Investigating Cancer (disponible en lignew6) fournit aux étudiants un aperçu du cancer. Elle introduit le concept selon lequel le cancer survient à cause d’anomalies dans la séquence ADN, explique les causes variées de ces mutations et présente l’activité et les feuilles de travail. Plusieurs sections de la présentation encouragent les discussions des étudiants (voir les notes de la présentationw6).
Dans la première partie de l’activité, les étudiants identifient les différences entre les séquences du gène KRAS dans des cellules saines et tumorales sur leurs feuilles de travail, et les marquent sur la bannière KRAS ou la feuille avec la séquence du gène.
Les feuilles de travail présentent les tracés du séquençage ADN brut de KRAS à partir d’échantillons de cellules saines et cancéreuses, représentés par des graphes de lignes colorées – une pour chaque région du gène. Les quatre bases sont représentées sur ces graphes par quatre couleurs différentes. Chaque pic coloré représente une base ADN particulière:
Rouge: T
Vert: A
Bleue: C
Noir: G (normalement ces pics sont jaunes mais ce n’est pas facile à lire sur papier)
Il y a 11 feuilles de travail numérotées au total, chacune montrant deux régions différentes du gène KRAS. Les six mutations se trouvant sur le gène KRAS sont sur les feuilles un à six, alors soyez sur de bien mélanger les feuilles avant de les distribuer à la classe. Tout doit être compléter pour assurer une pleine couverture du gène. Il est important de souligner aux étudiants que les mutations sont (relativement) rares, donc tout le monde n’en trouvera pas une; ce qui peut être utilisé pour explorer l’importance des données négatives et le traitement global dans les études scientifiques.
Identification des mutations
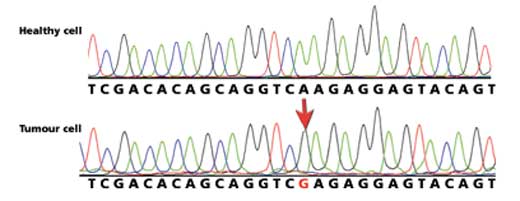
mutations de la séquence.
Cliquer sur l’image pour
l’agrandir
En utilisant les feuilles de travail, les étudiants compareront une section de la séquence ADN provenant d’une cellule saine et d’une cellule tumorale à partir du même patient. Le moyen le plus facile pour identifier si une mutation est présente est d’écrire la séquence ADN sous les pics colorés (pour aider, il y a un code couleur sur la feuille) et de comparer les séquences écrites.
Si une des lettres est différente (un pic a changé de couleur), cela indique une mutation dans la séquence. Dans la Figure 7 (à droite), le A dans la séquence ADN provenant de la cellule saine a été remplacé par un G dans la cellule tumorale.
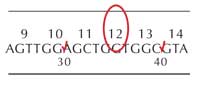
régions du gène qui ont été
vérifiées, et marquage des
mutations
Image reproduite avec
l’aimable autorisation de the
Wellcome Trust Sanger
Institute Communication and
Public Engagement team
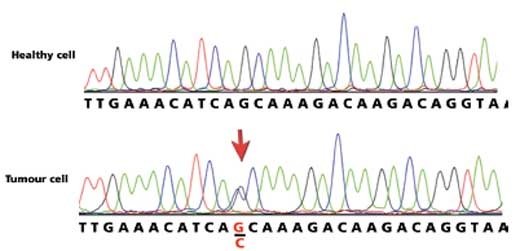
hétérozygote. Cliquer sur
l’image pour l’agrandir
Image reproduite avec
l’aimable autorisation de the
Wellcome Trust Sanger
Institute Communication and
Public Engagement team
Si les étudiants trouvent un double pic sur une position de base, cela devra être enregistré comme une alternative entre deux bases sur cette position, l’une au-dessus de l’autre. Dans la Figure 8, la séquence ADN saine a un G, tandis que la séquence tumorale a G et C. Ce n’est pas une insertion: cela représente une mutation hétérozygote où seule une copie du gène a substitué un C à un G. Dans ce cas, la séquence tumorale a remplacé G avec un C.
Tous les étudiants devront indiquer la région du gène qu’ils ont vérifié en cochant la région appropriée sur la feuille du gène (voir Figure 9, à gauche).
Les étudiants qui trouvent une mutation devront indiquer la base spécifique en l’encerclant sur la feuille du gène (voir Figure 9) et noter dans quel codon elle réside (dans cet exemple, codon 12).
Ils devront aussi remplir le tableau à la base de la feuille de travail, en utilisant la roue du code génétique pour traduire la séquence ADN en acide aminé, comme montré dans le Tableau 1:
| Numéro de l’acide aminé | Séquence ADN de la cellule saine | Séquence ADN de la cellule tumorale | Acide aminé de la cellule saine | Acide aminé de la cellule tumorale |
|---|---|---|---|---|
| 12 | GGT | GTT | Glycine (G) | Valine (V) |
Quand les mutations ont été trouvées, enregistrez-les sur la feuille de résumé des données (voir Tableau 2).
| Numéro de l’acide aminé | Séquence ADN de la cellule saine | Séquence ADN de la cellule tumorale | Acide aminé de la cellule saine | Acide aminé de la cellule tumorale |
|---|---|---|---|---|
| 12 | GGT | GTT | G (glycine) | V (valine) |
| 13 | GGC | GAC | G (glycine) | D (acide aspartique) |
| 30 | GAC | GAT | D (acide aspartique) | D (acide aspartique) |
| 61 | CAA | CGA | Q (glutamine) | R (arginine) |
| 146 | GCA | CCA | A (alanine) | P (proline) |
| 173 | GAT | GAC | D (acide aspartique) | D (acide aspartique) |
Discussion des résultats
Les résultats ci-dessus sont tous des substitutions d’une seule base. Ces mutations à l’intérieur de la région du gène KRAS codant la protéine peuvent être classées en trois types, selon l’information codée par le codon altéré.
- Les mutations silencieuses codent pour le même acide aminé.
- Les mutations faux-sens codent pour un acide aminé différent.
- Les mutations non-sens codent pour un codon stop et peuvent tronquer la protéine.
Discuter si les mutations sont significatives – ont-elles un impact sur la fonction de la protéine ou sont-elles “silencieuses”? Dans cette activité, les codons 30 et 173 sont silencieux et n’ont donc pas d’impact fonctionnel.
| Numéro de l’acide aminé | Healthy cell DNA sequenceSéquence ADN de la cellule saine | Séquence ADN de la cellule tumorale | Acide aminé de la cellule saine | Acide aminé de la cellule tumorale | Type de mutation | Significatif oui / non |
|---|---|---|---|---|---|---|
| 12 | GGT | GTT | G (glycine) | V (valine) | Ponctuelle (faux-sens) | Oui |
| 13 | GGC | GAC | G (glycine) | D (acide aspartique) | Ponctuelle (faux-sens) | Oui |
| 30 | GAC | GAT | D (acide aspartique) | D (acide aspartique) | Ponctuelle (silencieuse) | Non |
| 61 | CAA | CGA | Q (glutamine) | R (arginine) | Ponctuelle (faux-sens) | Oui |
| 146 | GCA | CCA | A (alanine) | P (proline) | Ponctuelle (faux-sens) | Oui |
| 173 | GAT | GAC | D (acide aspartique) | D (acide aspartique) | Ponctuelle (silencieuse) | Non |
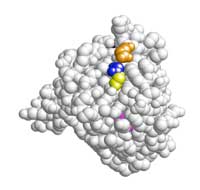
3D de la protéine KRAS. Les
acides aminés 12 (en bleu),
13 (en jaune), 61 (en orange)
et 146 (en rose) sont ceux
qui portent des mutations
Image reproduite avec
l’aimable autorisation de the
Wellcome Trust Sanger
Institute Communication and
Public Engagement team,
created with RasMol
La présentation a une image en 3D de la protéine KRAS (Figue 10, à droite); les diapositives 26 à 30 montrent où les mutations significatives se trouvent sur la protéine, et vous noterez qu’elles sont toutes dans la même région. Les codons 12, 13 et 61 ont été les premières mutations à être associées avec la transformation oncogénique dans la protéine KRAS; la mutation 146 a seulement été découverte en 2005. Utiliser ces diapositives pour discuter de l’impact que les mutations pourraient avoir sur la structure protéique et la fonction de KRAS dans la régulation de la croissance.
Comme activité optionnelle, les étudiants peuvent utiliser RasMol, le logiciel de modélisation moléculaire utilisé pour créer les images sur les diapositives 26-30, afin de souligner les acides aminés mutés dans la structure protéique. Voir les notesw6 pour l’enseignant pour les détails.
Comment une information comme celle-ci influence-t-elle notre approche du cancer?
Les notesw6 pour l’enseignant contiennent une abondance d’informations complémentaires, utilisant KRAS comme un exemple, pour stimuler la discussion sur la façon dont l’information génomique peut être utilisée pour approfondir notre compréhension du cancer et développer des traitements contre le cancer. Les points de discussion pour les étudiants incluent:
- Quelles expériences ou approches pourraient être utilisées pour établir quels cancers nécessitent les mutations de KRAS?
- Quels pourraient être les avantages de connaître cette information?
- Le cancer est une maladie génétique: il s’agit d’une suite de changements dans la séquence ADN. C’est pourquoi beaucoup de gens croit qu’un financement important de la recherche en génétique du cancer est le meilleur moyen de développer de nouveaux traitements anticancéreux et ainsi faire face à la maladie. Le traitement anticancéreux et les soins pour les patients nécessitent aussi de grandes quantités d’argent (le service de santé anglais, UK National Health Service, a dépensé plus de 2 Milliard de Livres uniquement pour les soins contre le cancer en 2000). Où et comment les étudiants pensent-ils que cet argent devrait être dépensé?
Web References
- w1 – Pour en savoir plus sur le « Cancer Genome Project » du « Wellcome Trust Sanger Institute »: www.sanger.ac.uk/genetics/CGP
- w2 – Pour en savoir plus sur le « Wellcome Trust Sanger Institute » à Hinxton, en Grande-Bretagne, un leader dans le « Human Genome Project », voir: www.sanger.ac.uk
- L’institut offre des visites aux classes scolaires, aux enseignants, au public, ainsi qu’un soutien pour les enseignants et d’autres opportunités pour s’impliquer. Voir: www.sanger.ac.uk/about/engagement
- w3 – Le site web « Yourgenome.org » a été lancé par le Sanger Institute pour stimuler l’intérêt et la discussion sur la recherche en génétique. Cela inclut une section de ressources variées et bien développées pour les enseignants, incluant l’activité présentée dans cet article. Voir: www.yourgenome.org
- w4 – Le « European Learning Laboratory for the Life Sciences » (ELLS) du « European Molecular Biology Laboratory » fournit des cours en formation continue (LearningLABs) en biologie moléculaire pour les enseignants européens en science du cycle secondaire. En Mars 2010, ELLS a organisé le premier LearningLAB en bioinformatique pour les enseignants au « European Bioinformatics Institute » en Grande Bretagne. Pour des informations sur les cours ELLS, aller s’il vous plaît sur: www.embl.org/ells
- w5 – Pour en savoir plus sur l’ »European Bioinformatics Institute », voir: www.ebi.ac.uk
- w6 – Pour télécharger tout le matériel pour l’activité KRAS et pour plus d’informations complémentaires, voir: www.yourgenome.org/teachers/kras.shtml
Resources
Sites web de référence pour les étudiants et la discussion
- Le site de la Recherche contre le Cancer anglais offre des informations sur tous les principaux cancers et la recherche actuelle. Voir: http://info.cancerresearchuk.org/cancerandresearch
- Le site du New Scientist a un domaine se concentrant sur le cancer, présentant les derniers articles sur l’évolution de la recherche contre le cancer et des animations interactives montrant les fonctions des médicaments ciblant le cancer. Voir: www.newscientist.com/topic/cancer
- Nature Milestones in Cancer offre une sélection d’articles de synthèse et une bibliothèque en ligne d’articles de recherche récents du Nature Publishing Group, disponible pour téléchargement en format PDF. Il présente également un calendrier indiquant les principales étapes dans la recherche contre le cancer. Voir: www.nature.com/milestones/milecancer
- Le site web multimédia « le Cancer de l’Intérieur » créé par le DNA Learning Center offre un guide multimédia en biologie, sur le diagnostic et le traitement du cancer. Voir: www.insidecancer.org
Nouvelles récentes
- Le site web de BBC News a publié un article intéressant sur la façon dont les points chauds génétiques nouvellement découverts dans le cancer de l’intestin pourraient aider les médecins à mieux traiter la maladie. Voir: http://news.bbc.co.uk ou utiliser le lien direct: http://tinyurl.com/28o7zgf
- Sample I (2009) First cancer genome sequences reveal how mutations lead to disease. The Guardian. Voir www.guardian.co.uk ou utiliser le lien: http://tinyurl.com/yeknj5x
- Roberts M (2009) Scientists crack ‘entire genetic code’ of cancer. BBC News. Voir http://news.bbc.co.uk ou utiliser le lien: http://tinyurl.com/yb59qcz
- Cet article inclut une interview vidéo avec le Professeur Mike Stratton, responsable du Cancer Genome Project.
Pour aller plus loin
- Friday BB, Adjei AA (2005) K-ras as a target for cancer therapy. Biochimica et Biophysica Acta – Reviews on Cancer 1756(2): 127-144. doi: 10.1016/j.bbcan.2005.08.001
- Futreal A et al. (2004) A census of human cancer genes. Nature Reviews Cancer 4: 177-183. doi: 10.1038/nrc1299
-
La version auteur de cet article peut être consultée librement en ligne. Voir: www.ncbi.nlm.nih.gov/pmc ou utiliser le lien direct: http://tinyurl.com/3x5hah6
-
Pour un catalogue complet des gènes de cancer somatique (COSMIC) décrit dans l’article ci-dessus et créé par le Cancer Genome Project, voir: www.sanger.ac.uk
-
- Stratton MR, Campbell PJ, Futreal AP (2009) The cancer genome. Nature 458: 719-724. doi: 10.1038/nature07943
- Télécharger l’article gratuitement ici, ou souscrire à Nature maintenant: www.nature.com/subscribe
- Pour plus d’informations sur la façon dont les mutations génétiques causent des maladies, voir:
- Patterson L (2009) Maîtriser les maladies génétiques. Science in School 13: 53-58. www.scienceinschool.org/2009/issue13/insight/french
- Pour une interview avec le chercheur sur le cancer, Joan Massagué, voir:
- Sherwood S (2008)Une nouvelle piste de traitement du cancer. Science in School 8: 56-59. www.scienceinschool.org/2008/issue8/joanmassague/french
- Lors d’une activité scolaire, pour discuter de l’éthique de savoir ce que vos gènes vous réservent, y compris la possibilité d’un cancer:
- Strieth L et al. (2008) Meet the Gene Machine: stimulating bioethical discussions at school. Science in School 9: 34-38. www.scienceinschool.org/2008/issue9/genemachine
Review
Les activités pédagogiques décrites dans cet article visent à impliquer activement les étudiants en biologie du second cycle dans la recherche de mutations qui pourraient potentiellement conduire au développement de cancer, en utilisant des données génomiques réelles. La procédure n’est pas vraiment expérimentale, ainsi aucun instrument réel de laboratoire n’est nécessaire. Au lieu de cela, la recherche est théorique basée sur des données authentiques. Tous les matériaux requis pour exécuter l’activité ainsi que le cheminement détaillé peuvent être téléchargés gratuitement à partir du site web du programme.
Outre la description des différentes étapes de l’activité, l’article et le site web associé comprennent des informations importantes sur ce que sont les cancers, ce qui les causes, comment ils se développent et comment les informations génomiques peuvent être utiles dans le développement de traitements. De plus, plusieurs points de discussion sont suggérés pour améliorer la compréhension des étudiants du cancer.
Michalis Hadjimarcou, Chypres