




Bioinformatica: la nuova ‘stanza delle meraviglie’ Understand article
La gestione dei ‘big data’ (grandi dati) nella biologia molecolare sta cambiando il modo in cui gli scienziati lavorano.
Nel XVI secolo, una stanza delle meraviglie (o Wunderkammer) era un modo popolare per sfoggiare una collezione privata di oggetti straordinari. Esemplari di animali, scheletri, minerali, insoliti oggetti fatti a mano e affascinanti antichità provenienti dal Nuovo Mondo potevano essere tutti mostrati in grande stile, suscitando nei visitatori un forte senso di curiosità in quella nuova era delle meraviglie.
Nel tempo, le stanze delle meraviglie hanno lasciato il posto ai più moderni musei. Come queste stanze, i musei soddisfacevano due tendenze profondamente umane: la curiosità e il desiderio di collezionare e preservare la conoscenza.
Oggi, queste stesse tendenze, insieme alla nuova tecnologia e ad uno tsunami di dati genetici, stanno determinando un cambiamento importante nelle scienze della vita: la democratizzazione dell’accesso. Oltre a catalogare il mondo visibile delle specie biologiche, gli scienziati possono ora sequenziare il DNA da milioni di specie e inserire le informazioni in database, insieme ad altri dati di biologia molecolare. Il risultato è un nuovo tipo di collezione: un catalogo di informazioni biologiche in costante crescita che può aiutare gli scienziati di tutto il mondo a dare un senso al mondo vivente.
Ma tutti questi dati devono essere gestiti, e la disciplina della bioinformatica – che combina la biologia con l’informatica – è stata sviluppata per occuparsi di questo.

Spencer Phillips/EMBL-EBI
Apertura della stanza
I laboratori di ricerca di tutto il mondo producono un’enorme quantità di dati, che vengono poi archiviati in database specializzati – come quelli dell’European Bioinformatics Institute (EMBL-EBI), situato vicino a Cambridge, Regno Unito w1. Una responsabilità chiave per l’EMBL-EBI è garantire che i dati contenuti siano pubblicamente accessibili, in modo che le ‘collezioni’ siano sempre aperte per i ricercatori di tutto il mondo. “Solo negli ultimi anni questo tipo di apertura è diventato praticabile, grazie al miglioramento dei canali di comunicazione, ma ora gli utenti lo prevedono”, afferma Andy Yates, team leader presso l’EMBL-EBI. “L’accessibilità ai dati è fondamentale per chiunque si occupi di scienza. Con una tradizionale stanza delle meraviglie, il collezionista era l’autorità suprema. Ora stiamo invece rendendo i contenuti – e noi stessi – aperti alla rianalisi e alla revisione. È una mossa necessaria se vogliamo che le nostre risorse siano veramente utili”, afferma.
Organizzazione dei dati

l’EMBL-EBI: il centro dati
ospita una grande quantità di
dati digitali, utilizzando
centinaia di server.
EMBL-EBI
Le tradizionali stanze delle meraviglie organizzavano gli oggetti per tipologia. Il moderno database organizza le risorse di dati biologici in modo simile – in categorie. Nel database, le informazioni e le categorie sono interconnesse, quindi il database è come una stanza delle meraviglie ‘intelligente’ o multidimensionale.
L’indicizzazione è essenziale oggi per le risorse pubbliche di dati così come lo era per le collezioni precedenti, per rendere i set di dati facilmente reperibili tra i petabyte di dati. Senza l’indicizzazione, non c’è modo di sapere cosa c’è in un database o come ci è arrivato. E anche le descrizioni dei set di dati – chiamate metadati – sono necessarie: “Senza metadati, esplorare un database è come vagare per i sotterranei del Louvre con gli occhi bendati, sperando di trovare la Gioconda”, afferma Yates.
Per rendere riutilizzabili da altri scienziati questi dati faticosamente acquisiti, i curatori di dati controllano attentamente la sottomissione dei dati per assicurarsi che soddisfino i requisiti necessari. Questi requisiti sono stabiliti in linee guida ampiamente accettate, conosciute con l’abbreviazione FAIR (findable, accessible, interoperable and re-usable): reperibili, accessibili, interoperabili e riutilizzabili. I set di dati di ricerca devono anche essere messi in un contesto e collegati alla pubblicazione scientifica che li descrive.
Visualizzazione dei dati
Oltre all’organizzazione, anche la visualizzazione dei dati è importante: essere in grado di ‘vedere’ le connessioni all’interno dei dati ispira le persone a continuare a esplorare. “La prima ovvia differenza tra una stanza delle meraviglie e un database è il contenuto”, spiega Jee-Hyub Kim, ex estrattore di dati (data miner) presso l’EMBL-EBI. “Da un lato, una collezione di oggetti fisici suscita subito una sensazione. Immagina solo cosa deve aver provato qualcuno che, magari senza aver mai nemmeno visto l’oceano, poteva guardare e toccare una stella marina o un corallo. È difficile creare questo tipo di rapporto con qualcosa di intangibile come i dati. Ecco perché servono una buona interfaccia e strumenti di visualizzazione per consentire all’utente di esplorare e interagire con un set di dati o un oggetto digitale.”
Un esempio di uno strumento di visualizzazione dei dati è la Protein Data Bank in Europe (PDBe, banca dati di proteine in Europa)w2, una risorsa per la raccolta, l’organizzazione e la diffusione di dati su strutture macromolecolari, come le proteine. Oltre ad essere un deposito centrale per gli scienziati che studiano le proteine, la PDBe consente agli utenti di vedere e interagire con modelli digitali tridimensionali delle proteine. Queste visualizzazioni sono accessibili da qualsiasi dispositivo connesso a Internet in tutto il mondo, inclusi telefoni e tablet.
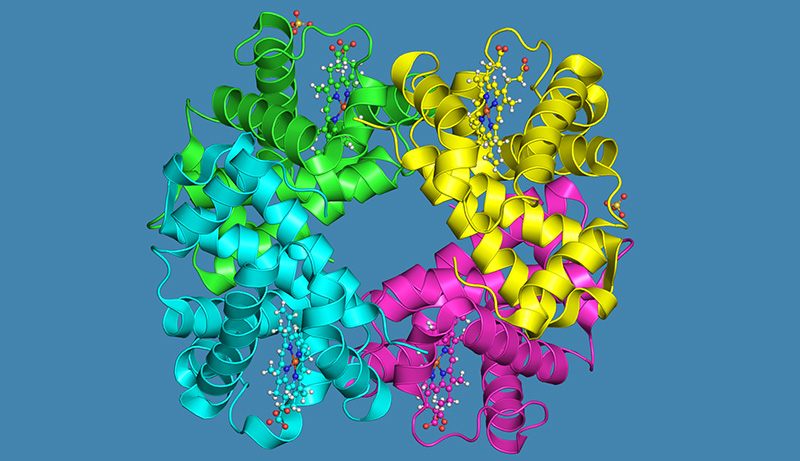
PDBe
Nuovi metodi, nuove conoscenze
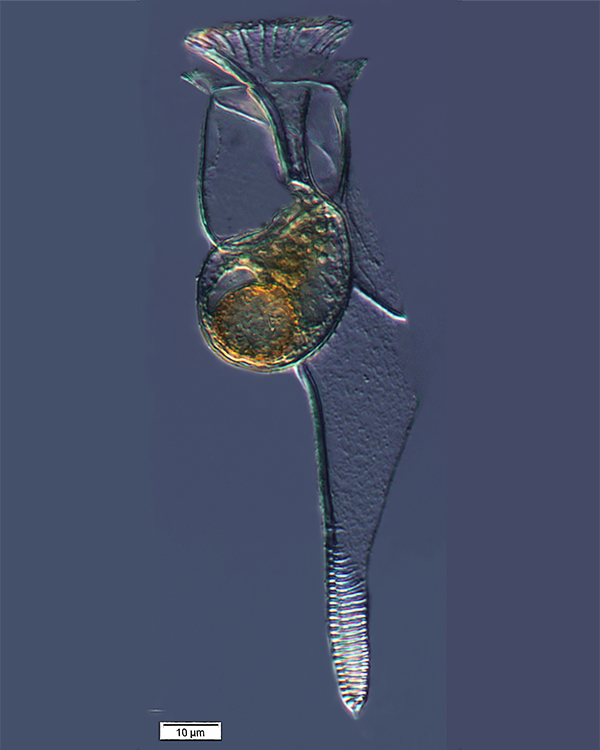
Histioneis elongata raccolto
dal team di Tara nell’Oceano
Pacifico del Sud
tintinnidguy/Flickr.com
Come la disponibilità di così tanti dati sta quindi cambiando il modo di fare scienza? Secondo Chuck Cook, responsabile dei servizi scientifici presso l’EMBL-EBI, gli scienziati diventeranno più dipendenti dai big data e coloro che non usano i big data saranno lasciati indietro professionalmente. “Man mano che diventiamo più specializzati, condurre esperimenti isolati sta diventando più difficile. Per approfondire la ricerca, avremo bisogno di collaborare con persone dai molti background diversi.”
“I biologi devono trasformarsi in programmatori, in una certa misura”, concorda Yates. “Ecco come stanno cambiando le questioni scientifiche. Il ricercatore formulerà un’ipotesi e poi la dimostrerà o lo smentirà attraverso l’estrazione di dati (data mining) da grandi risorse dati. Ciò richiede un certo grado di conoscenza di programmazione.”
Mentre iniziano ad analizzare questi set di dati su larga scala, gli scienziati stanno rivelando nuove conoscenze approfondite. Ad esempio, i dati delle spedizioni Tara Oceans, in cui una nave da ricerca ha percorso più di 300.000 km in tutto il mondo dal 2004, hanno portato alla scoperta di oltre 40 milioni di nuovi geni e stanno aiutando gli scienziati a comprendere gli ecosistemi invisibili che supportano la catena alimentare globale.
Gli scienziati durante il viaggio hanno raccolto sistematicamente campioni di plancton da tutti gli oceani del mondo e li hanno poi spediti a terra per il sequenziamento e l’analisi del DNA. “Sequenziare i campioni da Tara ci permette di ‘vedere’ parte della diversità della vita negli oceani”, afferma Rob Finn, un team leader nella metagenomica presso l’EMBL-EBI. “Il primo set di 40 milioni di geni identificati nei campioni di Tara Oceans sono principalmente procarioti – specie batteriche che non abbiamo mai visto prima. Ma nella seconda ondata di dati, abbiamo identificato oltre 117 milioni di geni eucarioti finora, e c’è ancora molta strada da fare”, afferma.
I dettagli concreti
Alla luce di questo afflusso di dati in continua crescita, quali saranno le grandi sfide per la biologia nei prossimi anni? “Prima dei dati aperti, uno scienziato lavorava su una proteina, un gene o un sistema sperimentale, di solito per tutta la sua carriera”, afferma la scienziata senior Janet Thornton, direttore emerito dell’EMBL-EBI. “Avere una visione d’insieme era praticamente impossibile. Oggi possiamo fare osservazioni sull’intero genoma e su tutte le specie”, afferma. Ma la dott.ssa Thornton pensa che questo cambiamento ponga anche la sfida più grande: le scoperte davvero importanti della biologia si trovano ancora nei dettagli concreti.
“Avremo ancora bisogno di guardare da vicino questi dettagli per rispondere a molte domande fondamentali, come perché gli organismi invecchiano?”, afferma. “Iniziative come lo Human Cell Atlasw3 (atlante delle cellule umane) sono ottimi esempi di quanti dettagli ancora ci mancano da capire prima di iniziare a spiegare come funzionano le cose. Il prossimo passo sarà tradurre queste conoscenze nelle aree quotidiane, come la medicina, l’agricoltura e la biodiversità.”
Proprio come i collezionisti che hanno creato le prime stanze delle meraviglie, gli scienziati stanno ancora meticolosamente catalogando tutto ciò che hanno imparato sulla forma e sulla funzione della vita e collegando tutto in modo da rendere possibili ulteriori scoperte.
Acknowledgement
Questo articolo è basato su un articolo pubblicato originariamente su EMBL etc., riprodotto per gentile concessione.
Web References
- w1 – EMBL-EBI è la casa dei big data in biologia. L’istituto ospita e condivide i dati da esperimenti di scienze della vita eseguiti in tutto il mondo e i suoi scienziati conducono ricerche di base sulla biologia computazionale. L’EMBL-EBI è uno delle sei sedi dell’European Molecular Biology Laboratory e si trova appena fuori Cambridge, nel Regno Unito.
- w2 – PDBe è un database per dati strutturali tridimensionali relativi a grandi molecole biologiche, come proteine e acidi nucleici. I modelli sono resi disponibili gratuitamente per scienziati e studenti di tutto il mondo.
- w3 – Lo Human Cell Atlas mira a mappare ogni singola cellula del corpo umano utilizzando tecnologie di sequenziamento a singola cellula. Questa collaborazione all’interno di tutta la comunità scientifica internazionale riunisce biologi, clinici, genetisti, programmatori e altri studiosi.
Resources
- Scopri di più sulle spedizioni Tara e la ricerca ecologica sul sito web di Tara.
- Per leggere un articolo di Science in School sulle spedizioni Tara, vedi:
- Peyrot R (2015) Tara: an ocean odyssey. Science in School 33: 6-11.
Institutions
Review
Questo articolo illustra un’idea fondamentale per molte discipline, dalle scienze naturali all’economia: l’enorme quantità di dati e conoscenze che ora possediamo deve essere organizzata professionalmente in modo che sia accessibile ai ricercatori di tutto il mondo.
Nell’insegnamento della biologia, l’articolo potrebbe essere utilizzato per introdurre il ruolo dei big data e della bioinformatica nella biologia molecolare e per evidenziare come le nuove tecnologie informatiche possono aiutare gli scienziati a confrontare e visualizzare sequenze di DNA e proteine. Ciò potrebbe incoraggiare gli studenti a esplorare da soli le molteplici possibilità che le tecnologie di comunicazione stanno aprendo nella scienza.
L’articolo potrebbe anche essere usato per incoraggiare la consapevolezza della straordinaria biodiversità che non è stata ancora scoperta negli oceani e in altri habitat naturali inesplorati.
Jesús López Alonso, insegnante di biologia, Istituto IES La Gándara, Spagna