




Mettendo a nudo il nostro profilo genetico Understand article
Tradotto da Anna Bertoni. Qual’e’ il ruolo della maggior parte del nostro DNA? Centinaia di scienziati hanno studiato per anni queste sequenze ‘spazzatura’ che potrebbero racchiudere la risposta a gravi malattie – e altro ancora.

concessa da fr73 / iStockphoto
Il Progetto Genoma Umano – il sequenziamento del genoma umano – e’ stato uno dei principali traguardi negli ultimi dieci anni: ha svelato l’architettura del genoma umano, tre miliardi di basi, ma la storia non finisce qui. Riuscire a comprendere come le nostre cellule interpretano questa sequenza, e’ fondamentale per capire come funziona il nostro genoma. Forse allora potremo usare questa conoscenza nella ricerca biomedica e sanitaria.
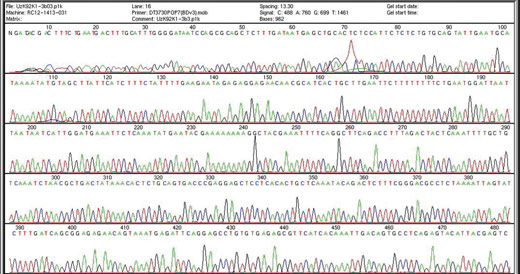
da un sequenziatore
automatico usato nel
Progetto Genoma Umano per
determinare la sequenza
completa del genoma umano.
Ogni picco corrisponde a
una specifica base. Il
Progetto Genoma Umano ha
identificato 3 miliardi di
lettere che compongono il
nostro genoma. Attualmente
il progetto ENCODE fornisce
informazioni su come
funziona il genoma. Cliccare
sull’immagine per
ingrandirla.
Immagine gentilmente
concessa da Genome Research
Limited
Una delle grandi sorprese del genoma umano e’ stata la scoperta che solo il 2% del genoma e’ costituito da geni, i quali contengono tutte le informazioni necessarie per fare le proteine. Dopo aver tenuto in considerazione ulteriori parti del genoma come gli RNA non-codificanti, regioni che hanno il compito di controllare l’attivita’ dei geni e degli introni (le parti della sequenza di un gene che vengono rimosse prima che l’RNA messagero e’ tradotto in proteina), si riteneva che il resto del genoma non avesse una funzione biologica. Per questo motivo veniva spesso indicato come DNA ‘spazzatura’.
Al di la’ della sequenza
Una volta terminato il sequenziamento del genoma, restava da comprendere se queste sequenze fossero davvero spazzatura. Nel 2003 e’ stato istituito il consorzio ENCODE con lo scopo di caratterizzare gli elementi non-codificanti ma funzionali del genoma. Il consorzio era supportato dal National Human Genome Research Institute negli Stati Uniti e guidato dall’European Bioinformatics Institute (EBI; vedi box) nel Regno Unito. La fase iniziale del progetto ENCODE si e’ svolta dal 2003 al 2007 e ha permesso ad una rete globale di ricercatori di testare, confrontare e ottimizzare metodi sperimentali e computazionali per identificare le parti attive in una frazione del genoma pari all’ 1% – in pratica spulciando un po’ nel genoma “spazzatura”.
Immagine gentilmente concessa da Ian Dunham
ha analizzato 147 tipi
cellulari diversi per capire le
differenze nella regolazione
del genoma in diversi tipi di
tessuto. Questo diagramma
evidenzia 47 tra i 147 tipi
cellulari usati nello studio.
Sono stati analizzati
molteplici tipi cellulari,
perche’ sebbene le cellule
contengono lo stesso
genoma, cio’ che varia e’ il
modo in cui questa
informazione viene usata nei
diversi tipi cellulari. Cliccare
sull’immagine per
ingrandirla.
Immagine gentilmente
concessa da Darryl Leja
I risultati iniziali sono stati pubblicati nel giugno 2007 (Il Consorzio del Progetto ENCODE, 2007) e hanno fornito una visione attraente sulla funzione del genoma. Per esempio, i dati ottenuti da esperimenti di microarray (vedi Koutsos et al., 2009) e sequenziamento hanno dimostrato che la maggior parte del genoma e’ trascritta, incluse le regioni che si ritenevano transcrizionalmente silenti (figura 2). Sebbene il ruolo biologico della maggior parte dei trascritti era ancora sconosciuto, e’ stato dimostrato che alcuni trascritti rappresentavano importanti regolatori dell’espressione genica. In generale, quest’istantanea del genoma ha rivelato che l’interazione tra geni, regioni coinvolte nella regolazione dell’attivita’ genica e altri tipi di sequenze di DNA era in realta’ molto piu’ complessa di quanto si fosse pensato. I dati hanno fornito una prima indicazione che il genoma contiene molte forme di elementi attivi e di conseguenza ci sono meno sequenze inutilizzate di quanto si era creduto.
Dopo aver testato con successo il loro approccio, i ricercatori di ENCODE hanno iniziato ad esaminare l’intero genoma. Questo e’ stato facilitato dai progressi nella tecnologia di sequenziameno del DNA e dalla disponibilita’ di saggi biochimici piu’ precisi.
La loro analisi ha sistematicamente mappato le caratteristiche del genoma, cosi’ come una mappa descrive un paesaggio e caratteristiche geografiche come foreste, fiumi e montagne. I ricercatori di ENCODE erano interessati a caratterizzare regioni del genoma marcate con segni ‘shhhh’ (tipi specifici di gruppi metile) che indicano il silenziamento genico, indicazioni come ‘lega qui’ per fattori trascrizionali, regioni amplificatore per aumentare la trascrizione, e modificazioni del DNA che controllano come il DNA e’ avvolto (figura 3).
Una marea di dati

ENCODE fossero stati
stampati, la carta impiegata
avrebbe riempito 12 bus.
Immagine gentilmente
concessa da marcus_jb1973
/ Flickr
Nel settembre 2012, dopo 5 anni di esperimenti ed analisi condotte da 442 ricercatori appartenenti a 32 istituti di ricerca nel Regno Unito, Stati Uniti, Spagna, Singapore e Giappone, il progetto ENCODE ha annuciato i risultati di quella che fino ad ora rappresenta la piu’ dettagliata analisi dell’intero genoma. Lo studio ha impiegato l’equivalente di 300 anni di tempo di calcolo per analizzare 15 terabyte di dati (15 x 1012 bytes) che sono attualmente disponibili al pubblico. Se i dati fossero stati stampati ad una densita’ pari a 1000 paia di basi per cm2, la torre di carta sarebbe stata alta 16 m e lunga piu’ di 30 m: l’equivalente del volume di 12 bus a due piani.
Il progetto ENCODE e’ un esempio di cio’ che puo’ essere raggiunto con progetti su larga scala basati sul contributo individuale di centinaia di ricercatori, ognuno dei quali ha aggiunto un tassello del puzzle per produrre un’immagine completa del genoma che non avrebbe potuto essere realizzata da una singola organizzazione.
Portando in vita la sequenza
Una delle scoperte piu’ entusiasmanti emersa dagli esperimenti di ENCODE, e’ che piuttosto di essere prevalentemente una sequenza non-funzionale, il nostro genoma e’ vivo e attivo: l’80% del genoma fa attivamente qualcosa. Cosa esattamente faccia rimane da scoprire, di certo il 9% di esso (e probabilmente molto di piu’) e’ coinvolto nella regolazione dell’espressione genica, e controlla quando e dove vengono fatte le proteine. L’80% del genoma attivo contiene piu’ di 70 000 promotori – i siti ‘lega qui’ per i fattori trascrizionali – e quasi 40 000 regioni enhancer – gli amplificatori che controllano l’espressione di geni distanti.
Un enorme pannello di controllo 3D

interruttori genici che
controllano in modo
complesso l’espressione
genica, il genoma umano
puo’ essere paragonato al
banco di missaggio di un
tecnico del suono.
Immagine gentilmente
concessa da Stuart Dallas
Photography / Flickr
Nel complesso, ENCODE ha identificato piu’ di 4 milioni di interruttori genici dispersi nel genoma. Si potrebbe immaginare il genoma come un enorme pannello di controllo, come il banco di missaggio di un tecnico del suono, con molti interruttori che accendono e spengono i geni. Questa informazione approfondisce la nostra comprensione dell’espressione genica e apre a nuove opportunita’ per la cura di malattie. Ad esempio, un piccolo cambiamento in un interruttore genico noto come CARD9 determina un aumento del 20% di rischio di sviluppare la sindrome di Crohn, una malattia infiammatoria dell’intestino. E se fosse possibile riportare gli interruttori genici alla situazione normale, spegnendo cosi’ in modo efficace le cause di una malattia?
I risultati di ENCODE hanno anche messo in evidenza come il genoma e’ organizzato e le interazioni fisiche che avvengono al suo interno. I ricercatori hanno scoperto che questi interruttori genici sono in contatto fisico con i geni che controllano, sebbene possano essere separati linearmente da centinaia di chilobasi. Noi tendiamo ad immaginare il genoma come una linea di sequenza lunga e diritta ma in realta’ esso e’ densamente avvolto nel nucleo della cellula, e questo permette a diverse parti del genoma di essere in stretto contatto l’una con l’altra.
Sulla base dei dati

permetteranno una miglior
comprensione della base
genetica delle malattie.
Immagine gentilmente
concessa da AlexRaths /
iStockphoto
ENCODE fornisce una mappa dettagliata del genoma e apre a nuove aree scientifiche da esplorare. Ian Durham dell’EBI e autore principale della pubblicazione di ENCODE spiega, “In molti casi si puo’ avere un’ idea di quali siano i geni coinvolti in una malattia, senza pero’ conoscere quali sono gli interruttori coinvolti. A volte questi interruttori sono sorprendenti – la loro localizzazione puo’ farli sembrare piu’ logicamente connessi ad una malattia completamente diversa. ENCODE ci fornisce una serie di indizi preziosi da seguire per scoprire i meccanismi chiave che entrano in gioco nella salute e nella malattia. Questi possono essere sfruttati per creare farmaci completamente nuovi, o per riutilizzare trattamenti esistenti.”
Olre a sapere quali geni sono coinvolti in una malattia, i ricercatori ora conoscono alcuni degli interruttori che controllano come questi geni vengono accesi e spenti. Questo sara’ particolarmente utile per interpretare i risultati di studi basati sulla popolazione che identificano i legami tra un gene ed una malattia. Unendo l’analisi funzionale del genoma condotta da ENCODE con i dati degli studi di associazione sull’intero genoma, i ricercatori possono mappare le variazioni genetiche che sono state collegate alla malattia con le regioni con funzione regolatoria, inclusi gli interruttori genici, identificati da ENCODE. I dati di ENCODE permetteranno una miglior comprensione della base genetica delle malattie e sosterranno il lavoro degli scienziati per molti anni a venire.
Per saperne di piu’ sull’EBI
L’European Molecular Biology Laboratory (EMBL)w1 e’ tra i migliori istituti di ricerca al mondo, dedicato alla ricerca di base nelle scienze biologiche. EMBL e’ internazionale, innovativo e interdisciplinare. I suoi dipendenti provengono da 60 nazioni e hanno formazioni scientifiche che includono biologia, fisica, chimica e informatica, e collaborano a progetti di ricerca che coprono l’intero spettro della biologia molecolare.
EBIw2, con sede vicino a Cambridge, nel Regno Unito, e’ parte di EMBL. L’EBI fornisce libero accesso ai dati originati da esperimenti biologici alla comunita’ scientifica mondiale, e si occupa di ricerca di base nella biologia computazionale. L’EBI e’ attivamente coinvolto nella formazione di ricercatori sia in ambito accademico sia industriale in modo da sfruttare al massimo l’enorme quantita’ di dati che vengono generati ogni giorno in esperimenti biologici.
EMBL e’ membro di EIROforumw3, l‘editore di Science in School.
References
- The ENCODE Project Consortium (2007) Identification and analysis of functional elements in 1% of the human genome by the ENCODE pilot project. Nature 447: 799-816. doi: 10.1038/nature05874
-
Scaricate l’articolo gratis dal sito web di Science in School qui, o abbonatevi a Nature adesso.
-
- The ENCODE Project Consortium (2012) An integrated encyclopedia of elements in the human genome. Nature 489: 57–74. doi: 10.1038/nature11247
-
Scaricate l’articolo gratis dal sito web di Science in School qui, o abbonatevi a Nature adesso.
-
- Koutsos A, Manaia A, Willingale-Theune J (2009) Fishing for genes: DNA microarrays in the classroom. Science in School 12: 44-49.
Web References
- w1 – Per saperne di piu’ su EMBL.
- w2 – Per avere maggiori informazioni sull’EBI.
- w3 – EIROforum e’ una collaborazione tra otto delle piu’ grandi organizzazioni intergovernative europee per la ricerca scientifica, che uniscono le loro risorse, strutture e competenze per sostenere la scienza in Europa e permetterle di raggiungere il suo completo potenziale. Nell’ambito delle sue attivita’ di educazione e divulgazione, EIROforum pubblica Science in School.
Resources
- Sul sito web di Nature potete accedere a ENCODE Explorer che vi permette di navigare tra i dati di ENCODE nelle sue 13 discussioni. Potete anche scaricare gratuitamente un poster (20 MB) che mostra un sottoinsieme dei dati di ENCODE.
- In un video online, Magdalena Skipper un editore di Nature e Ewan Birney dell’EBI discutono il progetto ENCODE.
- The Story of You: ENCODE and the Human Genomepresenta ENCODE in formato cartone animato.
- Ewan Birney dell’EBI, Tim Hubbard del Wellcome Trust Sanger Institute e Roderic Guigo del CRG presentano ENCODE in un video (sottotitoli in spagnolo).
- Per introdurre la bioinformatica nelle vostre lezione, perche’ non provare una delle seguenti attivita’?
-
Kozlowski C (2010) Bioinformatics with pen and paper: building a phylogenetic tree. Science in School 17: 28-33.
-
Communication and Public Engagement team (2010) Si può localizzare una mutazione legata al cancro? Science in School 16.
-
- Per saperne di piu’ sulla bioinformatica, vedi:
-
Hayes E (2011) Svante Pääbo, archeologo del genoma. Science in School 20.
-
Pathmanathan S, Hayes E (2007) Nicky Mulder, bioinformatician.Science in School 6: 75-77.
-
Institutions
Review
Questo articolo mette in evidenza uno dei piu’ recenti progressi nella genetica umana: il progetto ENCODE e come la sua ricerca e’ stata condotta.
Quando il codice genetico viene introdotto agli studenti, questi ultimi restano alquanto sorpresi dal fatto che solo il 2% del DNA umano codifica per le proteine mentre il restante viene considerato spazzatura. Il progetto ENCODE ha studiato la funzione di parte del DNA non-codificante, e ha dimostrato che non si tratta di spazzatura dopo tutto.
Se discutete con gli studenti del Progetto Genoma Umano, potreste anche introdurre ENCODE. Si suggerisce di fornire agli studenti conoscenze di base sulla regolazione genica, sulle malattie genetiche e loro cure, e sulle tecniche utilizzate nella ricerca genetica. Questo articolo potrebbe suscitare negli studenti un interesse per la bioinformatica, quindi si consiglia di incoraggiarli ad effettuare una ricerca nella letteratura scientifica riguardo al progetto ENCODE.
Namrata Garware, India